To Docker and Beyond!
by Malik Algelly and Hugo Haldi
Topics
Linux namespaces
Docker networks
Focus on User Namespaces
Capabilities
WTF are namespaces ?
- Wraps a global system resource for isolation
- Changes made to a resource within a namespace are visible to all the processes inside the namespace, but not to other processes
- One common use is containerization
Linux Namespaces
Existing namespaces
- UTS
- PID
- Mount
- Network
- User
IPC, Cgroup, Time, ...
UTS
- Isolate hostname and domain name between processes
- Changes made to the hostname from a process inside a UTS namespace are visible to all the processes within this namespace
- However, the processes outside the UTS namespace cannot see the changes
- A child fork inherit the UTS namespace of its parent
- When a process creates a new UTS namespace, hostname and domain name are inherited from the caller
Demo
$ hostname
ms-7917
# waiting for the new UTS
# namespace to change hostname
$ hostname
ms-7917
# change the hostname in the
# initial UTS namespace
$ hostname yggdrasil
$ unshare -u
$ hostname
ms-7917
# change the hostname in
# the new UTS namespace
$ hostname thor
$ hostname
thor
# wait for the initial UTS
# namespace to change hostname
$ hostname
thor
PID
- Isolate the process ID number space
- Different process in different namespaces can have the same PID
- The first process in this new namespace becomes the init process and get the PID 1 in this new namespace
- Useful to migrate containers between systems without inducing collisions.
- init becomes the parent of orphans processes inside the namespace
- when it dies, the kernel will terminate all its children via SIGKILL.
- PID namespaces have hierarchical relationship
- Processes from parents PID namespaces can see all the processes within the child PID namespaces. The opposite is not true.

Schema from this conference by Michael Kerrisk
Demo
$ sudo unshare -p -f
$ echo $$
1
$ ps
PID TTY TIME CMD
39352 pts/3 00:00:00 sudo
39353 pts/3 00:00:00 unshare
39354 pts/3 00:00:02 bash
49657 pts/3 00:00:00 ps
Mount
- Isolation of mount points per process
- Copy the mount namespace of the caller
Demo (contd)
$ sudo unshare -p -f -m
$ mount -t proc none /proc
$ echo $$
1
$ ps
PID TTY TIME CMD
1 pts/3 00:00:00 bash
32 pts/3 00:00:00 ps
Network
- Per process isolation on network devices
- One network device can be attached to exactly one network namespace
- We can use virtual network device pair to provide pipe-like tunnels between networks, attaching each element of the pair to a specific network namespace
- When a namespace is freed, a physical device is moved back to the initial network namespace while a virtual device is destroyed
Demo
ip netns add loki
ip link add eth0-l type veth peer name veth-l
ip link set eth0-l netns loki
ip link set veth-l up
ip address add 10.0.0.1/24 dev veth-l
ip netns exec loki ip link set lo up
ip netns exec loki ip link set eth0-l up
ip netns exec loki ip address add 10.0.0.2/24 dev eth0-l
References:
Docker Networks
Network types
bridge
host
overlay
ipvlan
macvlan
none
third parties
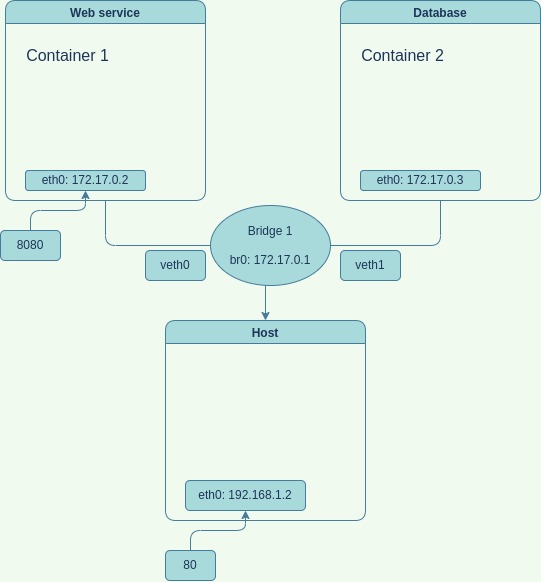
Bridge network
- Default network driver (when you don’t specify a network)
- Software bridge that is used to connect containers to communicate
- Only the containers connected to the same bridge can see each others
Host network
- Do not create a new network namespace
- Run the container inside the current network namespace
IPvlan L2
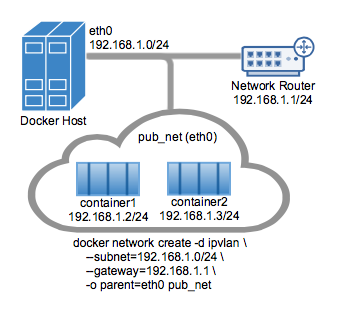
From the Docker documentation
MACvlan
Similar to IPvlan but assign a MAC adress to containers, making them visible as real devices on the network.
Useful for applications that analyse network traffic.
And more
None, Overlay, third parties drivers, …
User namespaces
- Isolate identifiers and attributes ({U,G}ID, root directory, capabilities, …)
- UID and GID can be different inside and outside a user NS
- Process can have unprivilieged UID outside a user NS, while having a UID of 0 inside the user NS.
- The process that creates the new user NS gains all the capabilities inside the new user NS.
Hierarchy
- User NS have a hierarchical relationship, every of them have a parent except for the initial user NS.
- User NS can have multiple children user NS
- Maxumim of 32 nested user NS.
- A process is member of exactly one user NS
- A user NS can own other NS (network, PID, …)
- Capabilities only apply to the resources that are member of the NS owned by the current user NS
- E.g. a process having
CAP_NET_ADMINcan only modify network interfaces that are in a network NS owned by the process user NS.

Schema from this conference by Michael Kerrisk
CAPABILITIES
From a binary privileges perspective
to a set of 41 capabilities
Goal?
If a program that has one or more capabilities is compromised, it has less opportunity to do damage than a root process
The way they should be seen
Rather than giving privileges to non-privileged processes,
allows you to remove privileges from the all powerful root
Thread capabilities sets
- Each user namespace has 5 sets of capabilities that define the capabilities owned, those that can be earned and those that can be passed on through forks.
- The sets: Effective, Permitted, Inheritable, Bounding, Ambient
Thread capabilities sets
Effective : used by the kernel to any privilege check
Permitted : can be obtained with capset system call
Inheritable: can be inherited after an execve
Bounding : used to limit the capabilities that are gained during execve
Ambient : are preserved across an execve of a program that is not privileged.
File capabilities sets
The kernel supports associating capability sets with an executable file, similar to setuid.
Each file has 3 sets of capabilities
Effective, Permitted, Inhenitable
File capabilities sets
File capability sets are stored in an extended attribute named security.capability.
Writing to this attribute needs the CAP_SETFCAP capability.
File capability sets, in combination with the thread capability sets, will determine the capabilities of a thread after an execve.

File capabilities in Docker
Docker imposes some limitations with file capabilities.
Extended attributes are removed when Docker images are built.
“This means you will not normally have to concern yourself too much with file capabilities in containers."
dockerlabs
Exploits
CVE-2019-5736: A runC vulnerability
Principle
Exploit procfs and runC.
/proc/self/exegives a symlink to the current process executable path/proc/self/fdis a directory containing the file descriptors open by the process- runC is a container runtime for Docker (default)
Vulnerability
- Allows a malicious container to overwrite the host
runcbinary - Can exploit any of this two situations:
- Creating a new container using a malicious image
- Attaching (
docker exec) into an existing container which the attacker had previous write access to
- When creating or attaching to a container, runC creates a
runc initsubprocess to setup all needed restrictions on itself to prevent the called process to escape the container - Then
runc initwillexecvethe requested binary and create a new process inside the container
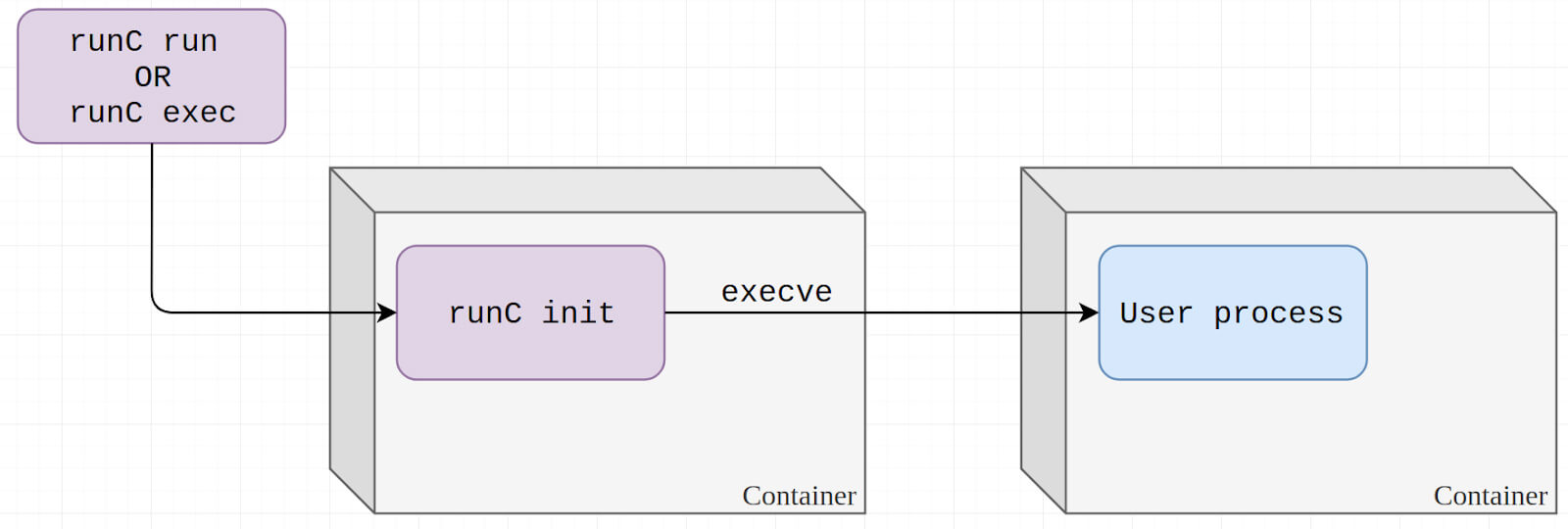
The attack consist in replacing the binary to execute by /proc/self/exe so runc init will execute itself
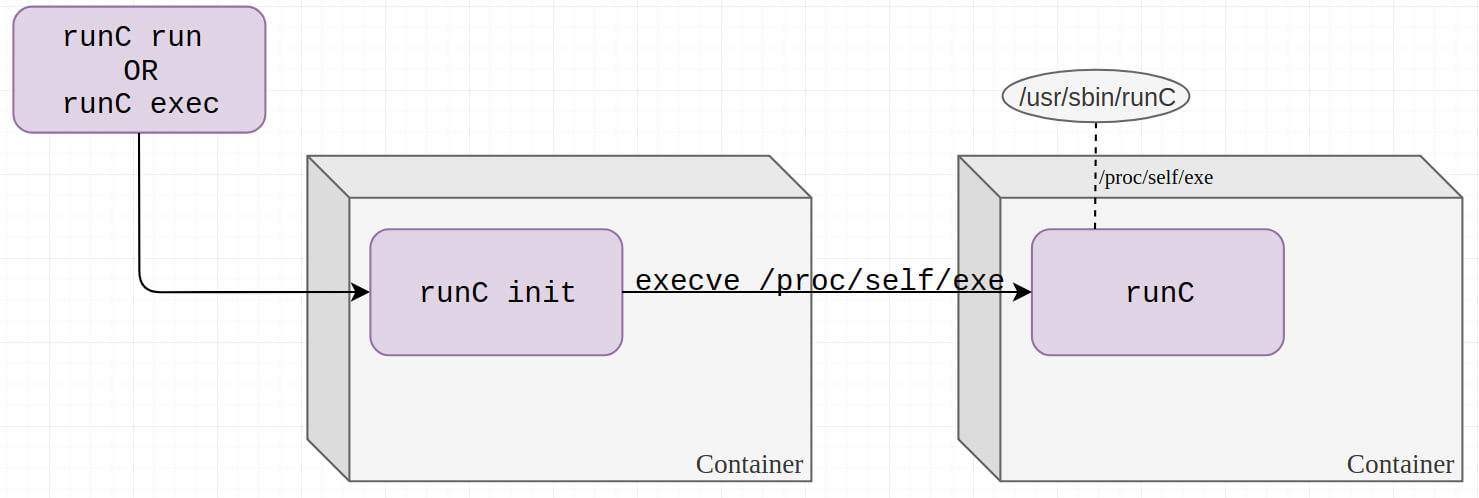
Why is it working ? /proc/self/exe should be a symlink to something like /usr/sbin/runc, so execve should try to execute /usr/sbin/run from the container right ?
procfs is a special filesystem. /proc/[pid]/exe does not follow the normal semantics for symlinks. When a process open /proc/[pid]/exe the kernel gives access to the open file entry directly.
However, we cannot overwrite the runC binary while the process is running. But if the runC process exits, /proc/[runc-pid]/exe will disapear and we will lose the reference to the runC binary.
So we have to:
• first identify the PID of runC
• then open in read only /proc/[runc-pid]/exe
• finally, wait that runC exits to open in write mode /proc/self/fd/[ro-runc-fd]
Once the runC binary has been replaced, the system is infected and the attacker can gains root access to the host.
This breach has been patched by copying the runC executable inside a temporary filesystem so that any modifications made on runC will be discarded.
References and images:
Exploit capabilities: CAP_SYS_MODULE
Principle
- Run an infected image with CAP_SYS_MODULE capability
- Exploit the kernel module injection within a running container
- Open a reverse shell to a listening socket in the attacker system
We create a container with a malicious image and give the CAP_SYS_MODULE capability to the container. The image contains a kernel module that will create a reverse shell to the attack IP address.
The command insmod will insert a module into the kernel. Since we gave the CAP_SYS_MODULE capability to the container, the syscall will succeed and modify the host kernel.
Demo
The container has to run as root, as for the docker engine, otherwise the syscall will be denied.
The moral of this story is that you have to pay attention to what privileges and capabilities you give to a container, try to run containers as non-root user or use user namespace ID binding, and use root-less docker engine if you can.
References:
Questions
- Describe (in details) the state of the capabilities sets of a child process after a fork
- How you would couter the patch to the CVE-2019-5736 ?
(joke)
Questions (more seriously)
- Give one example of good security practice with containers.
- What is the objective of using containers ?